
There are 3 types of
1. Absolute xpath
2. Relative xpath
3. Partial xpath
Let us go through each one of them one by one:
1. Absolute xpath : It uses complete path from the root element to the desired element.The key characteristic of Absolute XPath is that it begins with the single forward slash(/) , whichhtml ' always.
Absolute
Below is an example of absolute
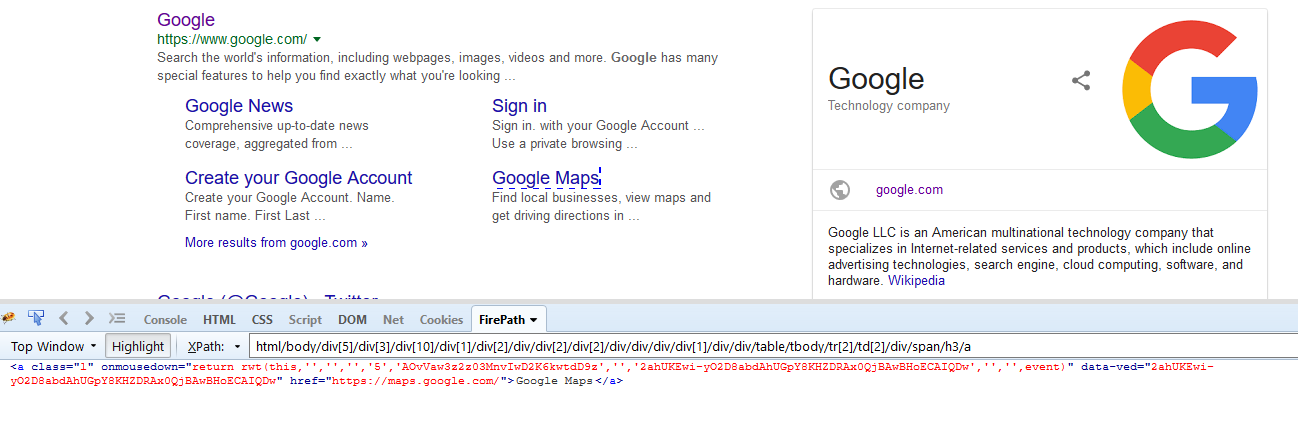
In the above snap we can see that the xpath for Google maps starts from the tag html -this is the root node, which indicates the beginning of the DOM structure. From html
2. Relative Xpath :
As we have seen in the above Google maps example, the absolute xpath that is generated is very lengthy and there are high chances that this xpath would vary with every release due to addition or removal of UI elements. To avoid frequent occurrence of 'No such element found' error we can use relative xpaths .
Relative xpath searches for matching element anywhere in the HTML DOM.
It starts with a double slash(//) which indicates to search an element anywhere on the HTML DOM.
Basic syntax for this is:
//tagname[@attribute_name='attribute_value']
3. Partial Xpath(Dynamic xpath ):
Dynamic/Custom xpaths are used to narrow down the matching nodes which helps to efficiently identify web elements.
They are also used to create xpaths of webelemnts that change each time when a webpage loads.
There are various ways in which we can create dynamic xpaths which will be explained one by one below:
1.Using contains() and starts with()
2.Using AND and OR conditions
3.Using multiple attributes
4.Using Siblings
5.Using Ancestors
1.Using contains() and starts-with():
These functions can be used in the below situations:
- When the HTML properties/attributes are not very clear for any
webelement . - When we want to create a list of elements having
same partial value - When the values of attributes are dynamic
Syntax for contains:
- By text-//tagname[contains(text(),'anytext')]
- //tagname[contains(.,'text')]
Consider below example,xpath for 'Create an account' text is created using contains function

In the above xpath '.' can be replaced by text() method.The only difference is
Eg. //span[contains(text(),'Create an account')]
By Attribute:
//tagname[contains(@attribute_name,'attributevalue')]
Let us look at the below example where we have created an
If sometimes the html attributes are not very clear as in below example then we can use partial attribute name using contains().

Using starts-with()
- Similar to contains(),starts-with() function can be used to create partial
xpaths . In situations where the attribute values are not clear starts with can be used.For eg.
In the below example the value of attribute class is a bit since there is a space between the 2 words,hence we can use starts-with function here

2.Using AND and OR conditions
In OR expression, two conditions are used, whether 1st condition OR 2nd condition should be true. It is also applicable if any one condition is true or maybe both. Means any one condition should be true to find the element.
In the below XPath expression, it identifies the elements whose single or both conditions are true.
Xpath=//*[@type='submit' OR @name='btnReset']
Highlighting both elements as "LOGIN " element having attribute 'type' and "RESET" element having attribute 'name'.
Similarly AND condition can also be used that combines 2 attributes:
Below is an xpath to identify Experience button in naukri profile:

3.Using multiple attributes:
Multiple attributes can be used to create unique
Consider below example
Below we have created

But in order to locate Today's

Using
XPath axis defines a node-set relative to the current node. Names of axes include “ancestor”, “descendant”, “parent

.png)

.png)



















.png)




.png)










0 Comments:
Post a Comment