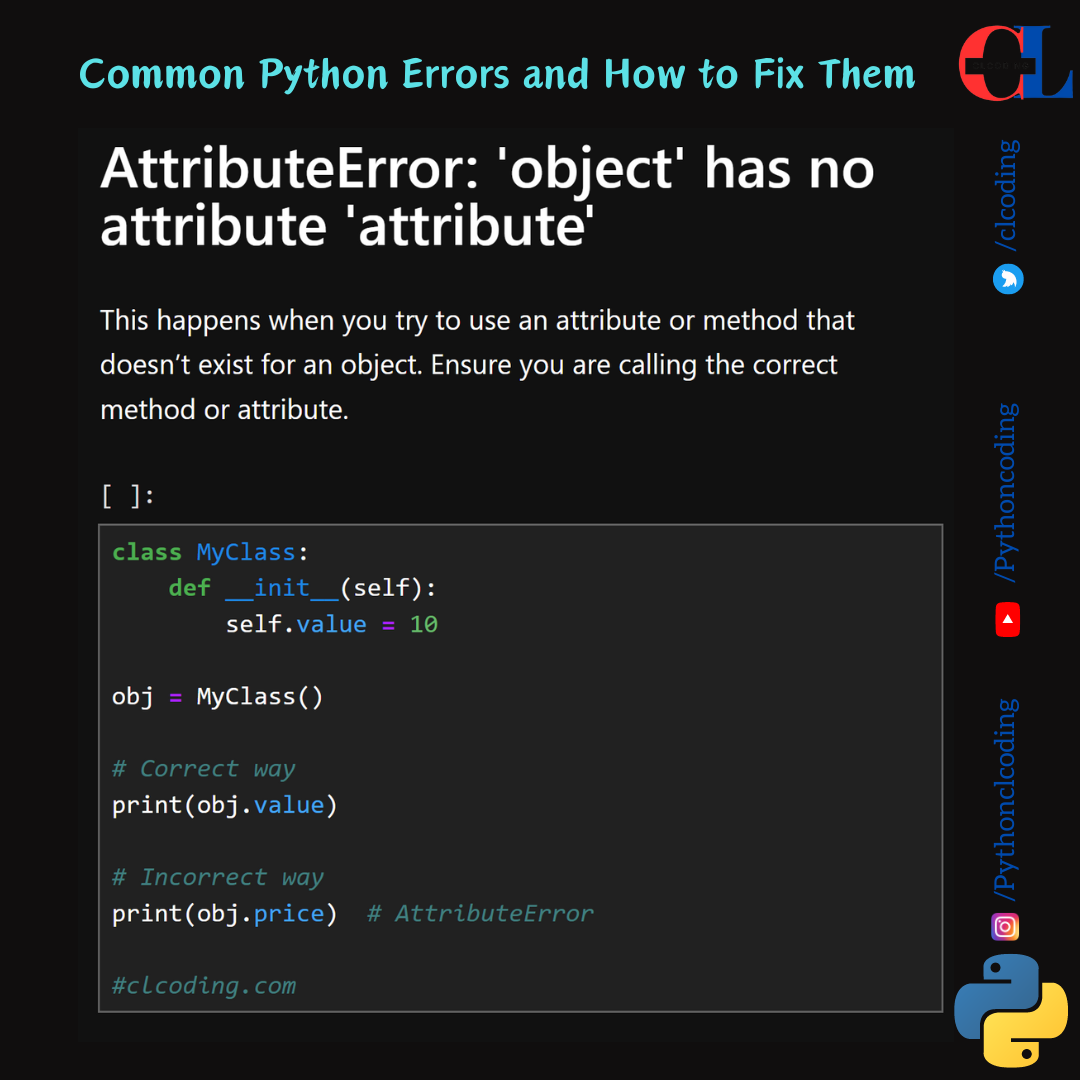
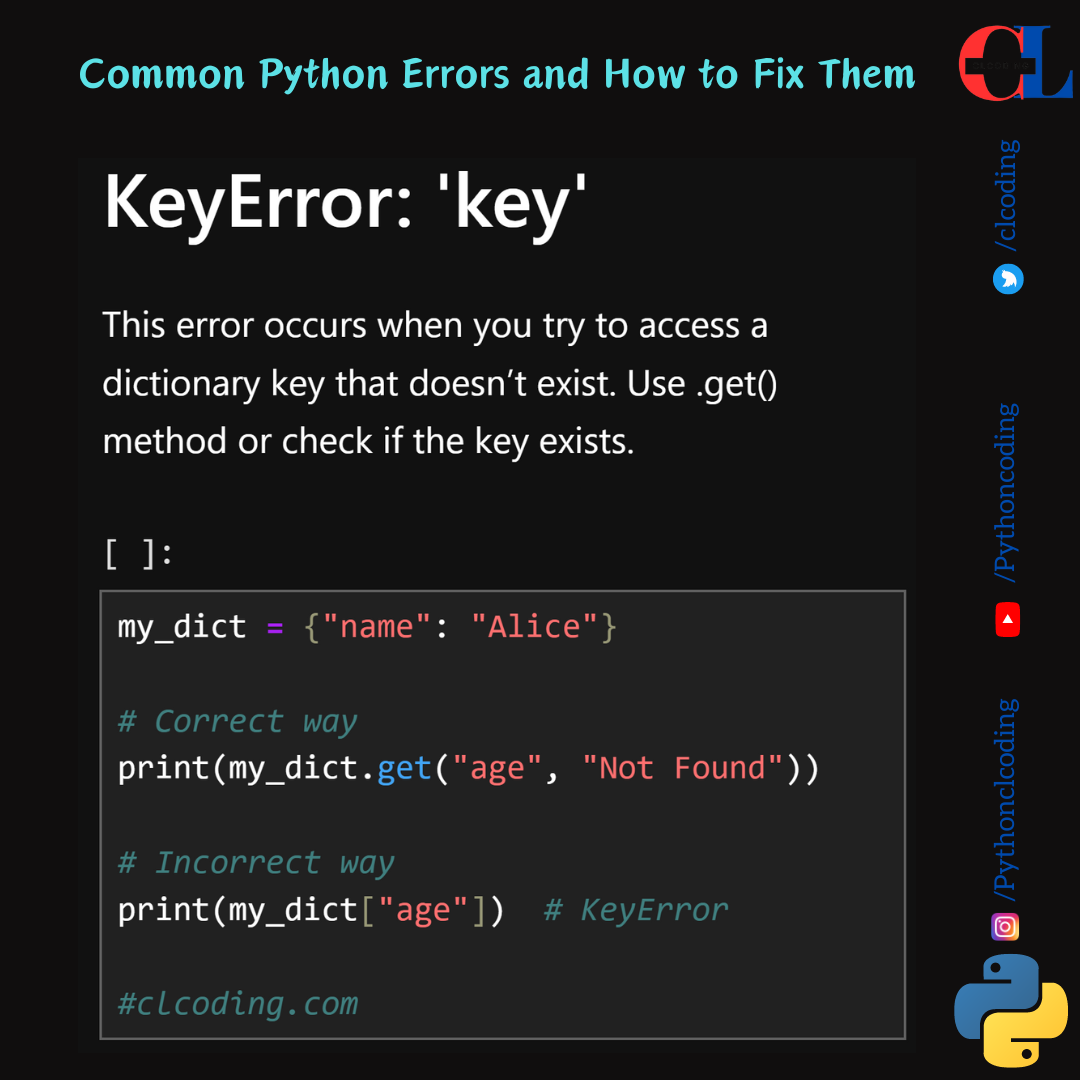
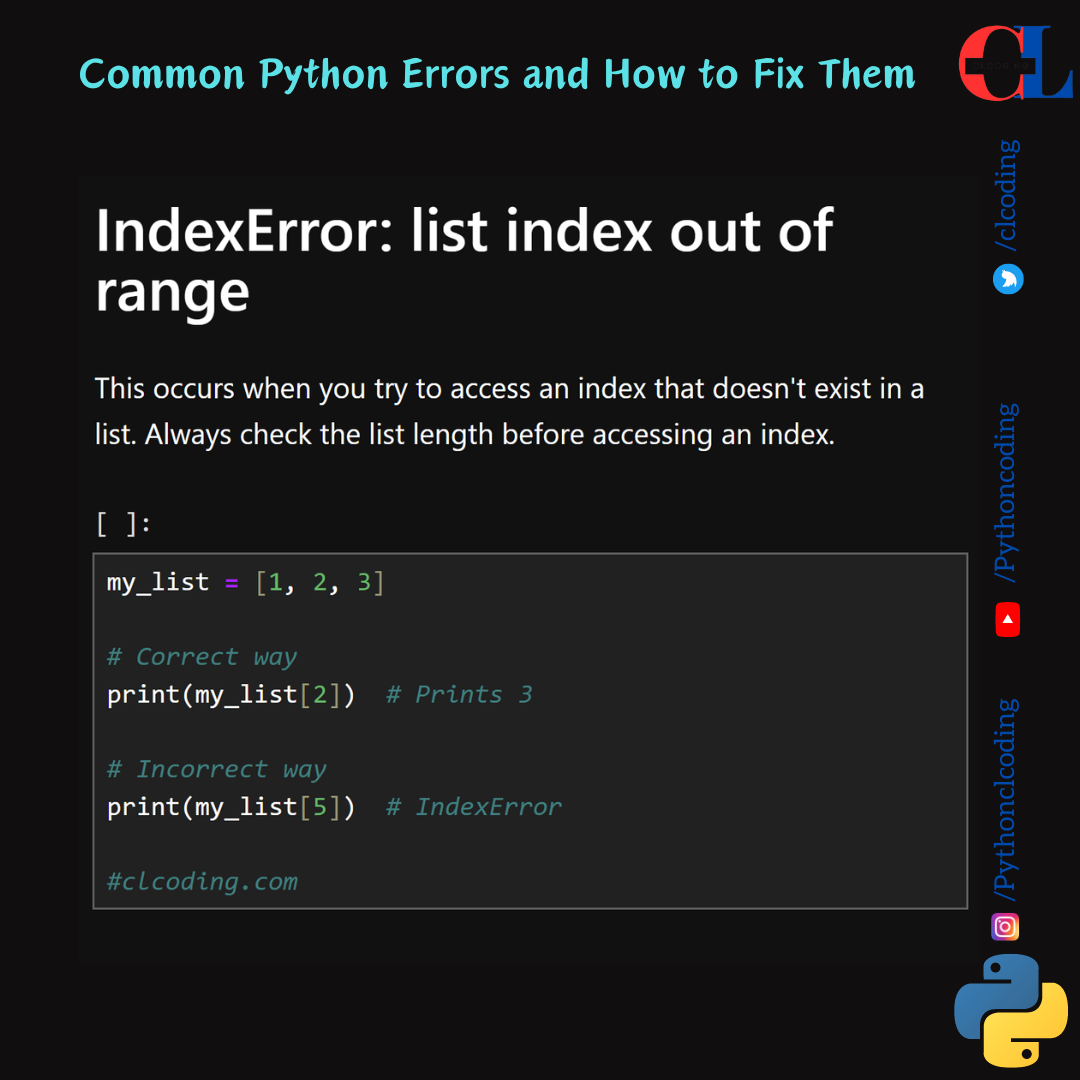
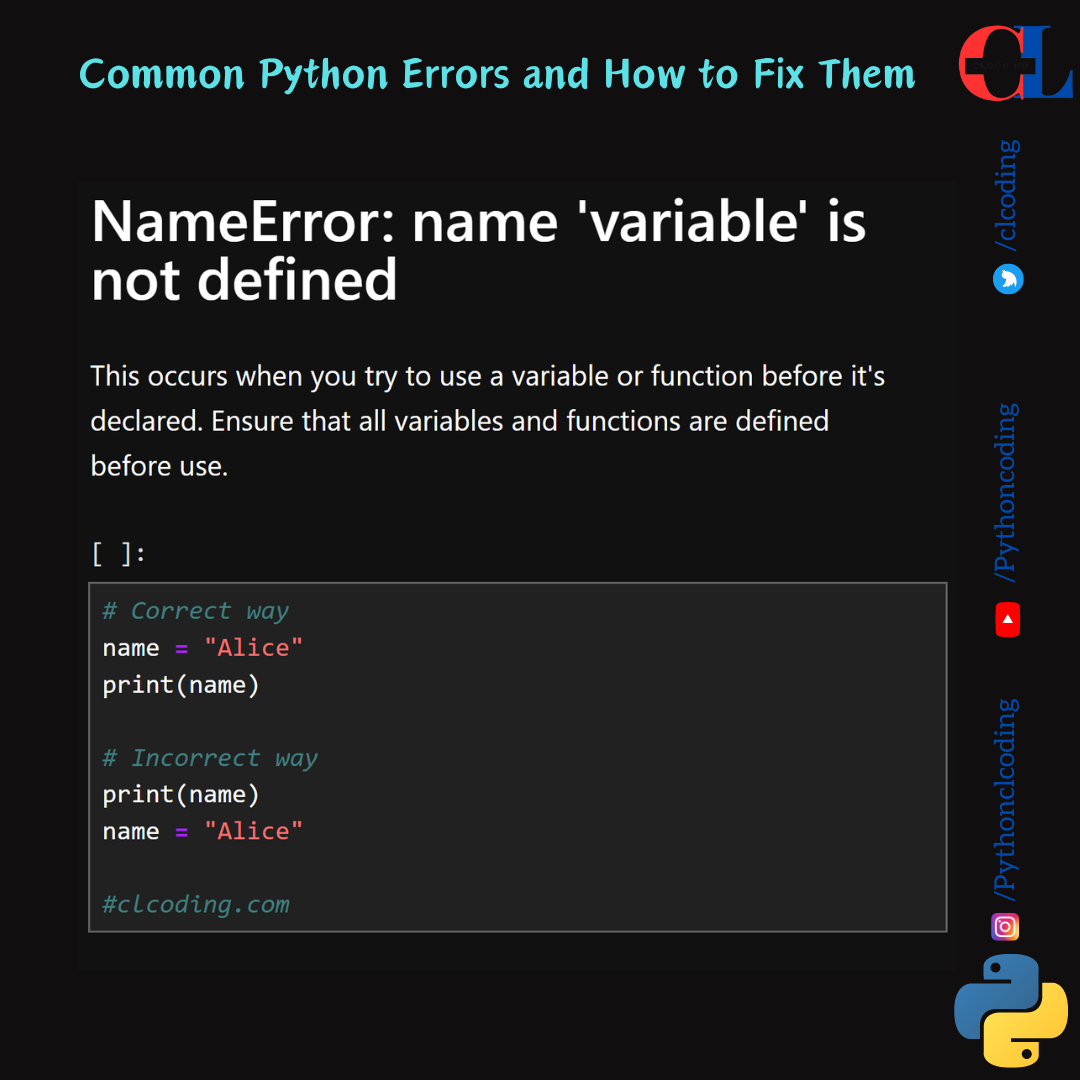
let's break down and explain each part of this code:
my_dict = {1: 0, 0: [], True: False}
result = all(my_dict)
print(result)
Step-by-Step Explanation
Dictionary Creation:
my_dict = {1: 0, 0: [], True: False}
This line creates a dictionary my_dict with the following key-value pairs:
1: 0 - The key is 1 and the value is 0.
0: [] - The key is 0 (or (0) in another form) and the value is an empty list [].
True: False - The key is True and the value is False.
Note that in Python dictionaries, keys must be unique. If you try to define multiple key-value pairs with the same key, the last assignment will overwrite any previous ones. However, in this dictionary, the keys are unique even though 1 and True can be considered equivalent (True is essentially 1 in a boolean context).
Using the all Function:
result = all(my_dict)
The all function in Python checks if all elements in an iterable are True. When all is applied to a dictionary, it checks the truthiness of the dictionary's keys (not the values).
In this dictionary, the keys are 1, 0, and True.
The truthiness of the keys is evaluated as follows:
1 is True.
0 is False.
True is True.
Since one of the keys (0) is False, the all function will return False.
Printing the Result:
print(result)
This line prints the result of the all function. Given that the dictionary contains a False key (0), the output will be False.
Summary
Putting it all together, the code creates a dictionary and uses the all function to check if all the keys are true. Since one of the keys is 0 (which is False), the all function returns False, which is then printed.
So, when you run this code, the output will be:
False
.png)






.png)