
Automation involves identifying the elements on the UI and performing actions on them, so in order to identify the UI
In some cases if these elements are not found using other locators such as Id, Class, Css etc then Xpaths are used.
What is
XPath (XML Path Language) is a query language for selecting nodes from an XML document.
Xpath language provides the ability to navigate around XML tree and select the nodes by various criteria.
Below is an example of XML tree:

In this example Product is the Root Element of the tree and the two child nodes of Product are Name and Detail
Understanding HTML Dom
Whenever a web page is loaded, the browser creates a Document Object Model of the page.
The HTML DOM is a standard object model and programming interface for HTML. It defines:
The HTML elements as objects
The properties of all HTML elements
The methods to access all HTML elements
The events for all HTML elements
In other words: The HTML DOM is a standard for how to get, change, add, or delete HTML elements.
The HTML DOM is constructed as a tree of objects:

In order to start studying about
Consider the below HTML DOM of

Let us concentrate on the highlighted portion of the DOM:
Here "input" is a tag and "class,data-type,name ,aria-required,placeholder aria-label and id" are known as attributes.Each of these attributes have some values which are used for creating the html page.
When should
Elements on any UI can be located using various
1. The attributes that are supported by selenium webdriver are not present
2. The attributes that are available are not unique.
In such
Basic syntax of xpath:
//tagname[@attribute_name='attribute_value']
Explanation:
//-Selects nodes in the document from the current node that match the selection no matter where they are
@-Selects attribute
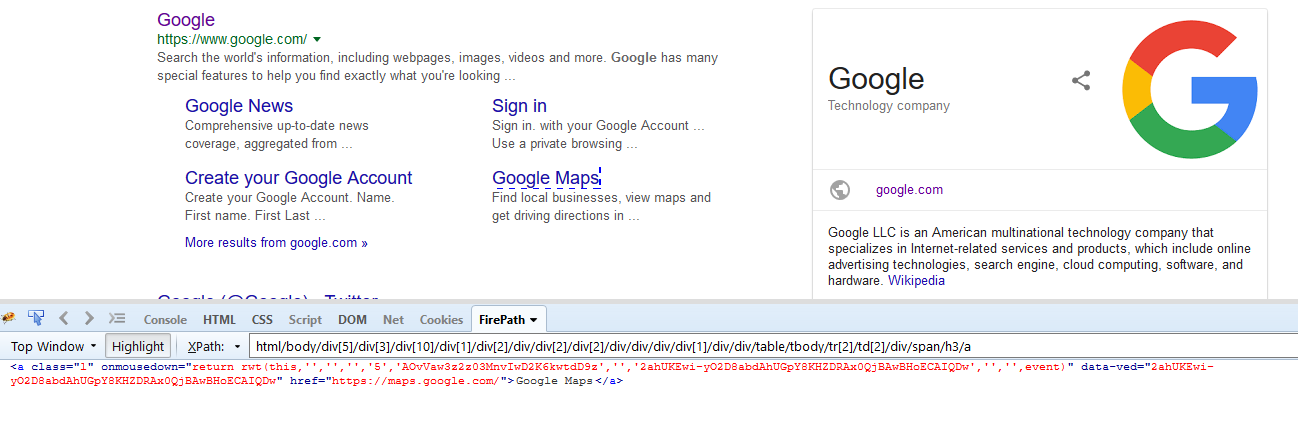
Let us look at a simple example below

We have created an
In the
Typing the above












.png)
.png)

.png)



















.png)
.png)

.png)





