
.png)
- Write Readable Code: Use descriptive variable names and write comments where necessary.
- Follow PEP 8: Adhere to Python's official style guide for formatting your code.
- Use Virtual Environments: Isolate project dependencies using virtualenv or venv.
- Keep Code DRY: Avoid duplication by creating reusable functions and modules.
- Write Modular Code: Break your code into modules and packages.
- Use List Comprehensions: For simple loops, prefer list comprehensions for readability and performance.
- Handle Exceptions: Use try-except blocks to handle exceptions gracefully.
- Use Context Managers: For resource management, use context managers (with statements).
- Test Your Code: Write unit tests to ensure your code works as expected.
- Leverage Built-in Functions: Python has a rich set of built-in functions; use them to simplify your code.
- Optimize Imports: Import only what you need and organize imports logically.
- Document Your Code: Write docstrings for modules, classes, and functions.
- Use Meaningful Docstrings: Provide useful information in docstrings, including parameters, return values, and examples.
- Adopt Version Control: Use git or another version control system to manage your code changes.
- Automate Testing: Use CI/CD tools to automate your testing and deployment.
- Use Type Hints: Add type hints to your function signatures to make your code more readable and maintainable.
- Avoid Global Variables: Limit the use of global variables to reduce complexity.
- Keep Functions Small: Write small, single-purpose functions.
- Optimize Performance: Profile your code to find bottlenecks and optimize them.
- Stay Updated: Keep your Python and library versions up to date.
- Use Pythonic Idioms: Write code that takes advantage of Python’s features, such as tuple unpacking and the else clause in loops.
- Practice Code Reviews: Regularly review code with peers to catch issues early and share knowledge.
- Avoid Mutable Default Arguments: Default argument values should be immutable to avoid unexpected behavior.
- Use Logging: Instead of print statements, use the logging module for better control over log output.
- Be Careful with Floating Point Arithmetic: Understand the limitations and potential inaccuracies.
- Leverage Generators: Use generators to handle large datasets efficiently.
- Understand Variable Scope: Be aware of local and global scope and use variables appropriately.
- Use Proper Indentation: Follow Python’s strict indentation rules to avoid syntax errors.
- Encapsulate Data: Use classes and objects to encapsulate data and functionality.
- Implement str and repr: Provide meaningful string representations for your classes.
- Avoid Premature Optimization: Focus on readability and maintainability first; optimize when necessary.
- Understand the GIL: Be aware of the Global Interpreter Lock and its impact on multithreading.
- Use Efficient Data Structures: Choose the right data structure for the task (e.g., lists, sets, dictionaries).
- Avoid Deep Nesting: Keep your code flat and avoid deep nesting of loops and conditionals.
- Adopt a Consistent Naming Convention: Follow naming conventions for variables, functions, classes, and modules.
- Use Enum for Constants: Use the Enum class to define constants.
- Prefer f-Strings: Use f-strings for string formatting in Python 3.6+.
- Leverage Dataclasses: Use dataclasses for simple data structures (Python 3.7+).
- Handle Resources Properly: Ensure files and other resources are closed properly using with statements.
- Understand List vs. Tuple: Use lists for mutable sequences and tuples for immutable sequences.
- Use Decorators Wisely: Understand and use decorators to extend the behavior of functions and methods.
- Optimize Memory Usage: Be mindful of memory usage, especially in large applications.
- Adopt a Code Formatter: Use tools like Black to format your code automatically.
- Use Static Analysis Tools: Employ tools like pylint, flake8, and mypy to catch potential issues early.
- Understand Slicing: Use slicing effectively for lists, tuples, and strings.
- Avoid Anti-patterns: Recognize and avoid common anti-patterns in Python programming.
- Keep Learning: Continuously learn and stay updated with the latest Python features and libraries.
- Contribute to Open Source: Contributing to open-source projects helps improve your skills and gives back to the community.
- Write Secure Code: Be aware of security best practices and write code that minimizes vulnerabilities.
- Refactor Regularly: Regularly refactor your code to improve its structure and readability.

.png)






.png)


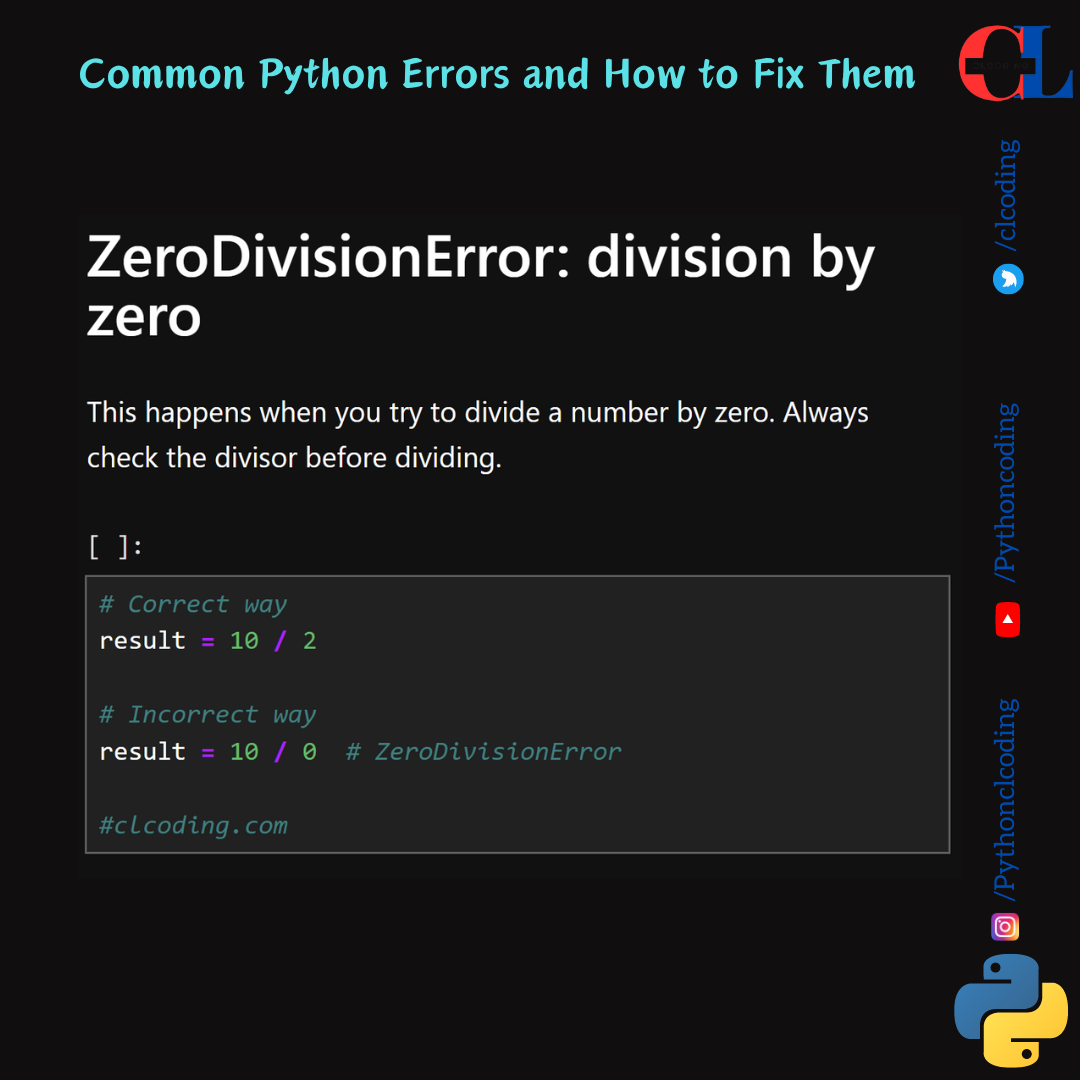
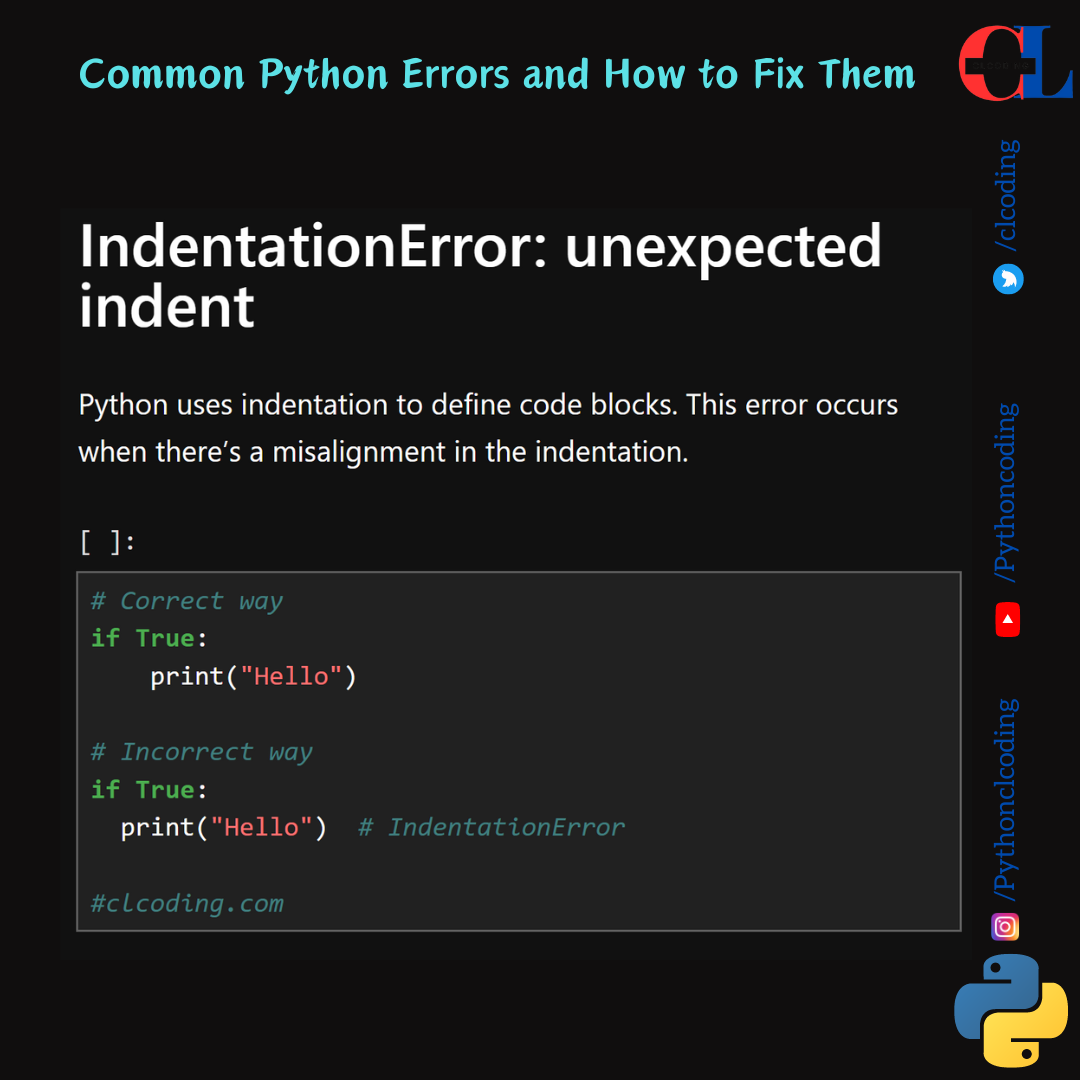
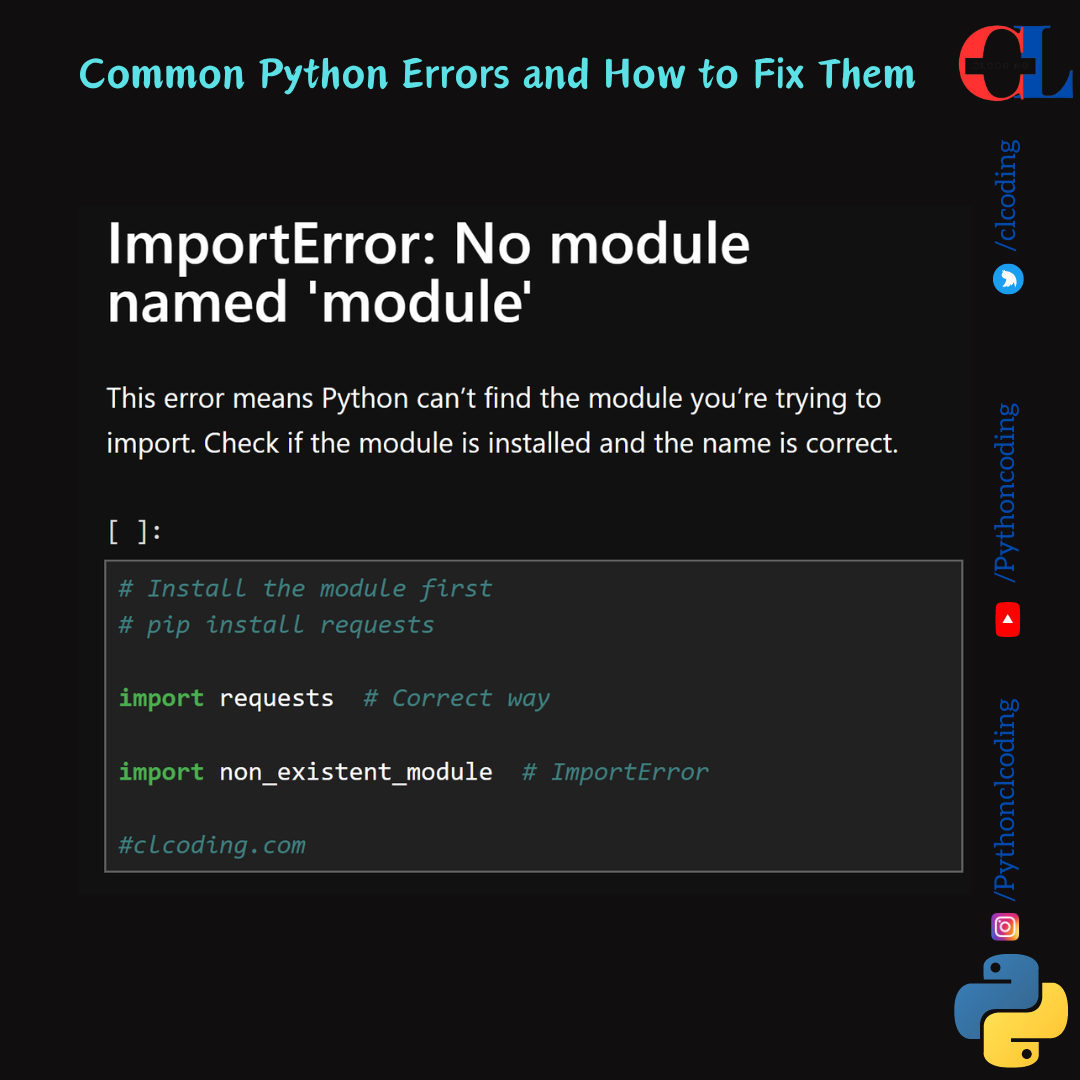
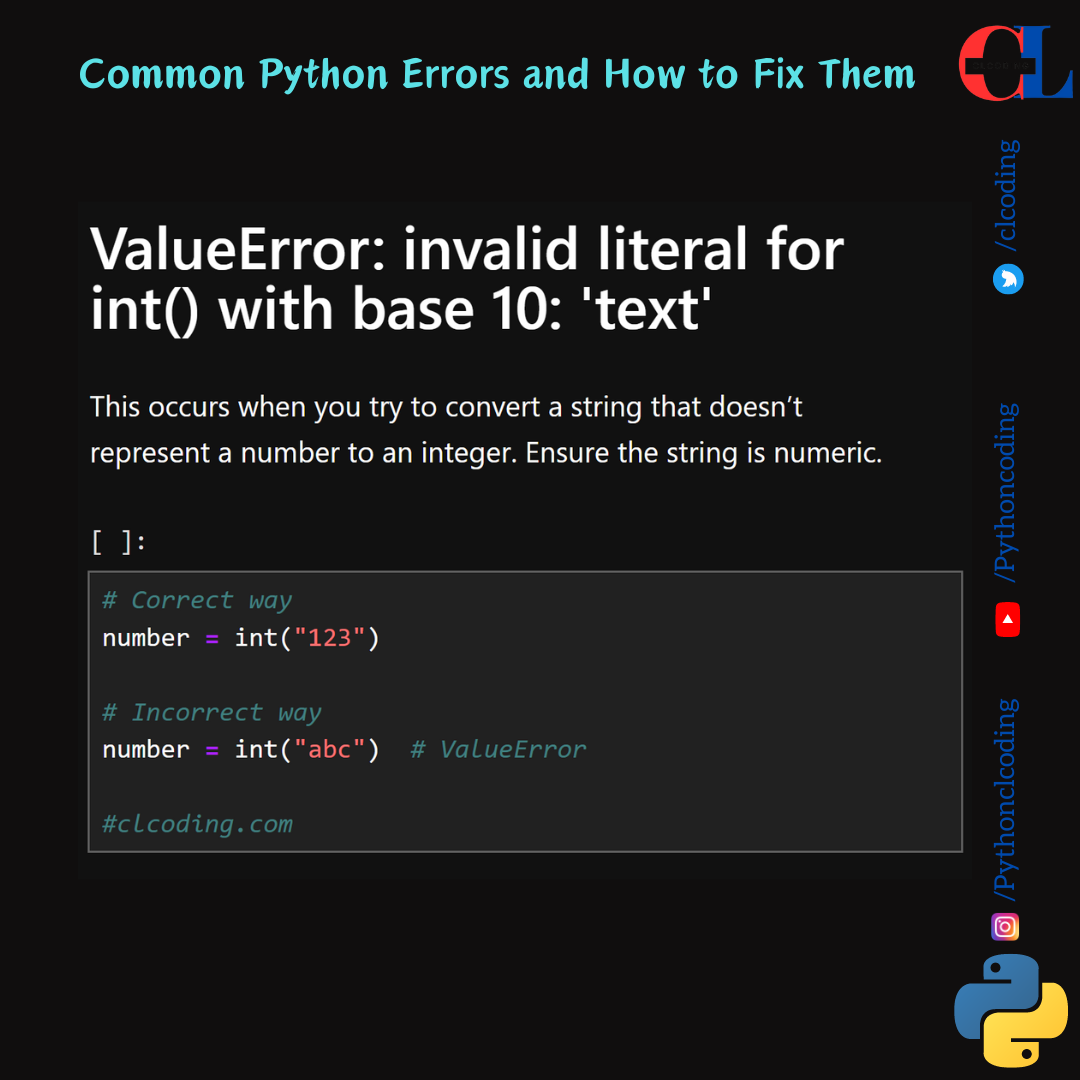
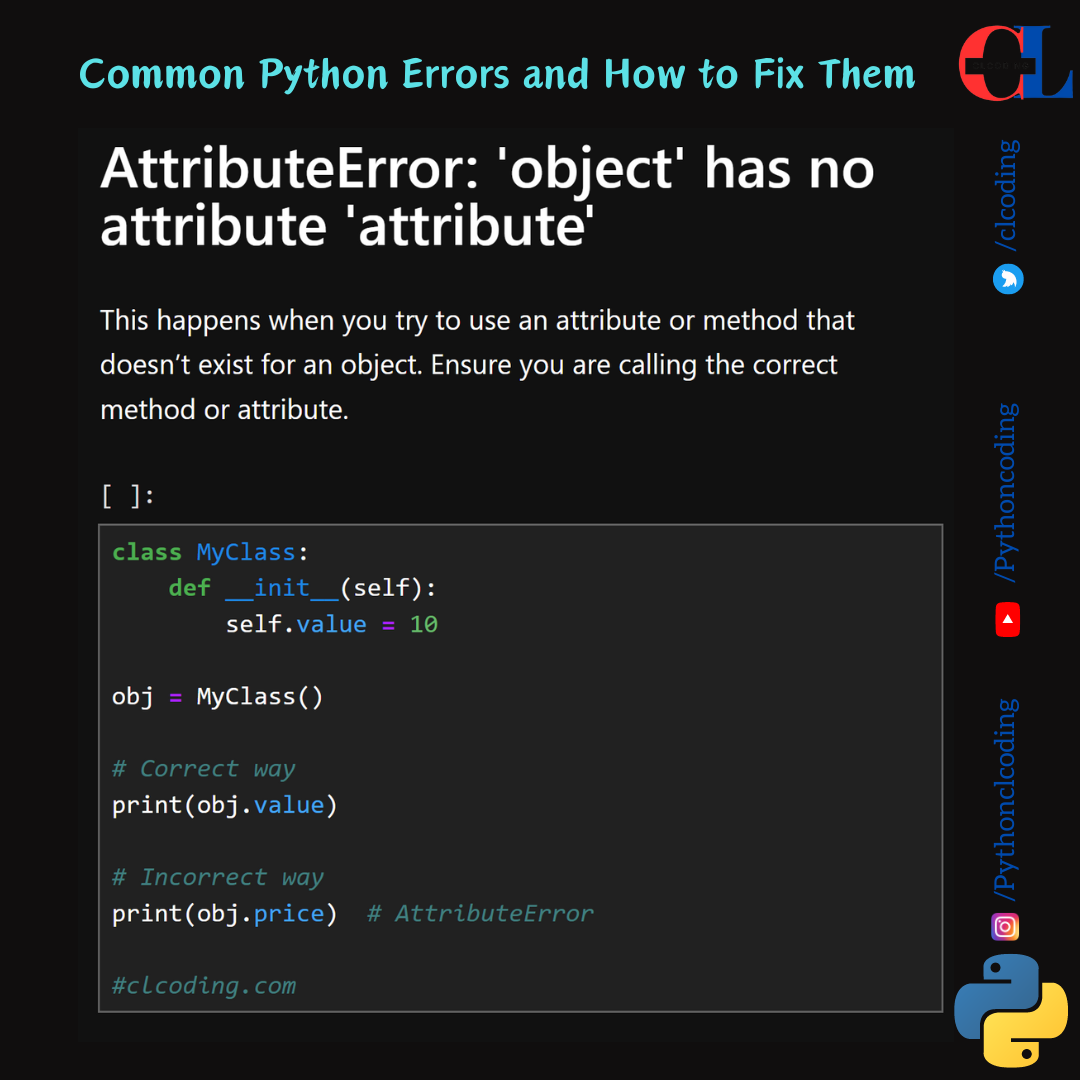
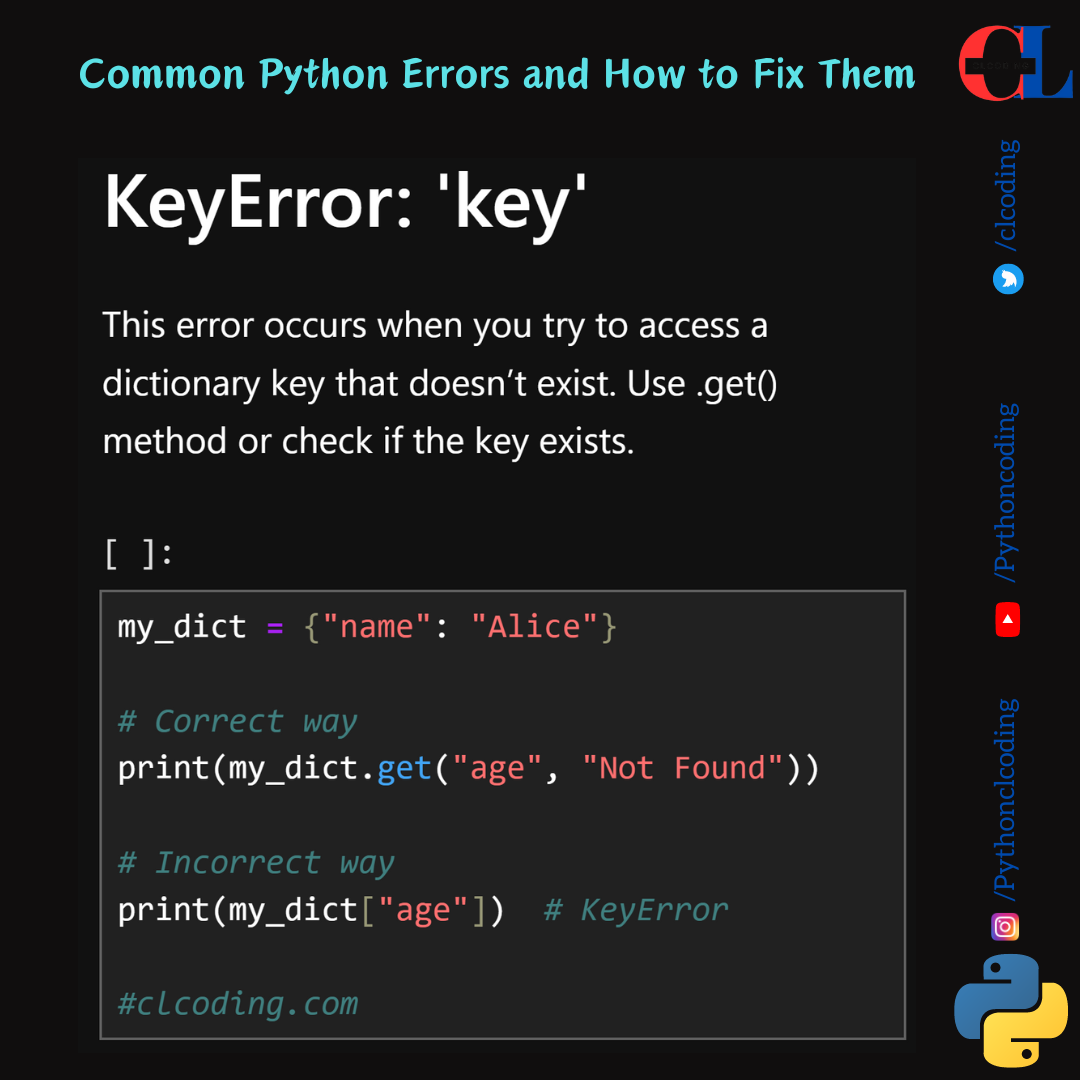
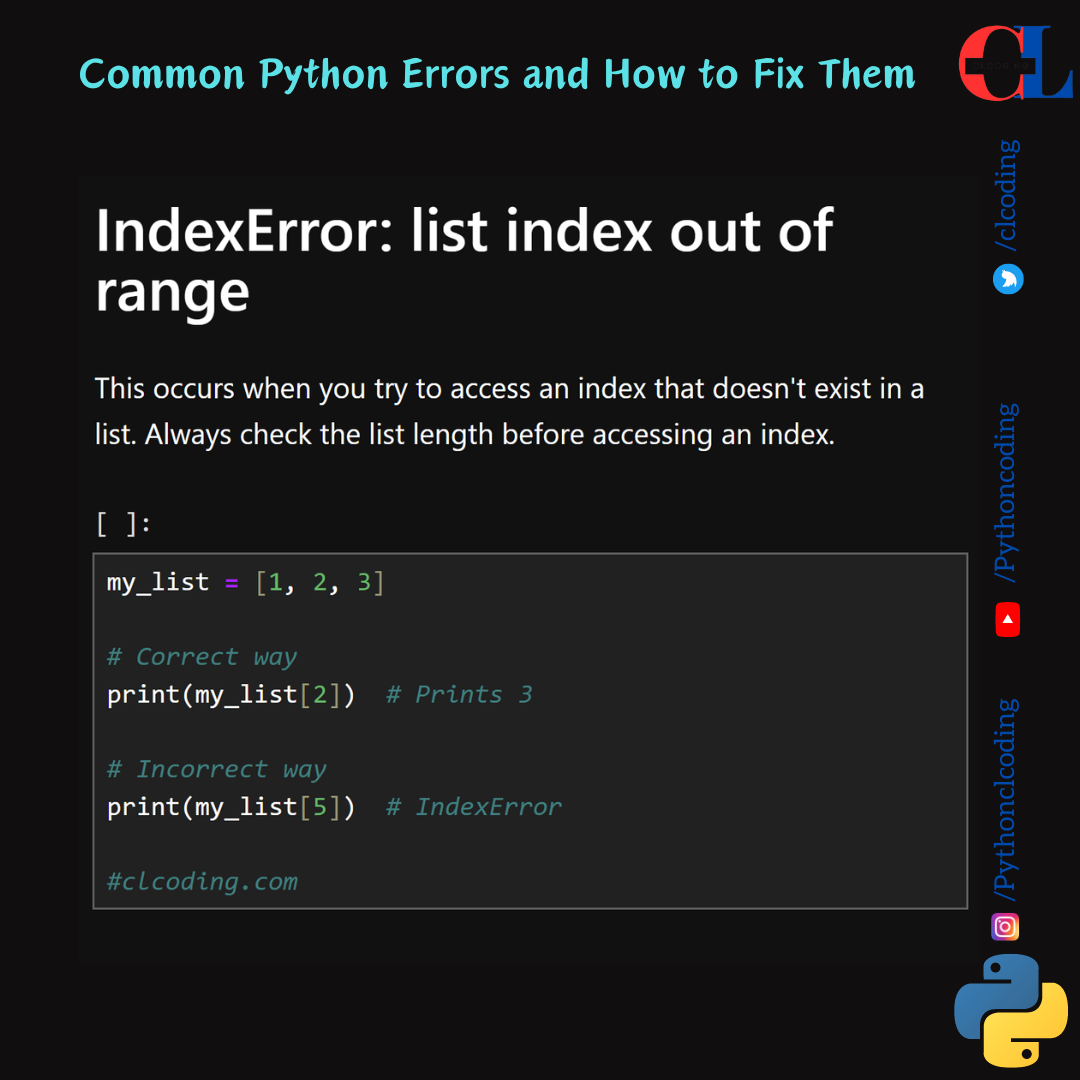

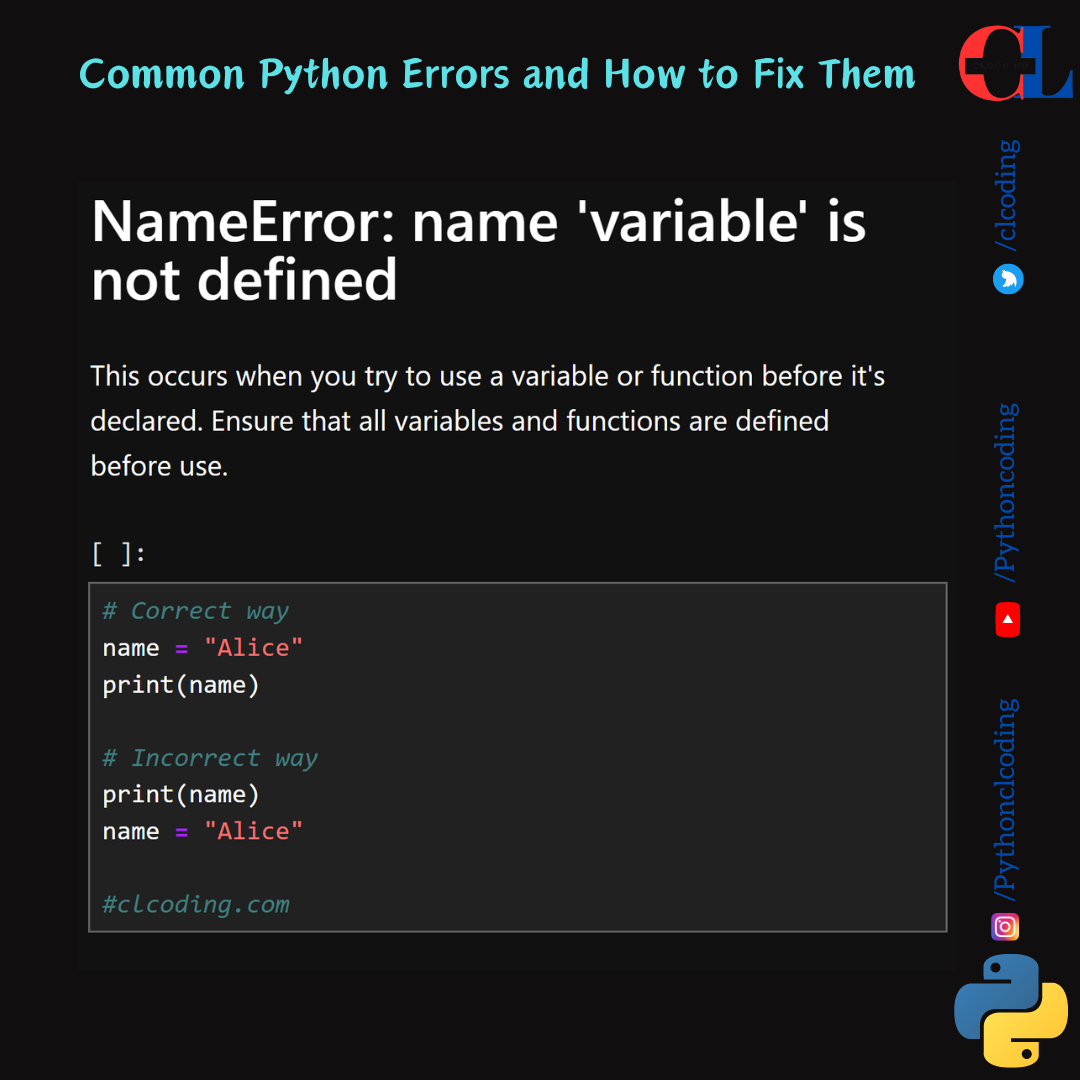
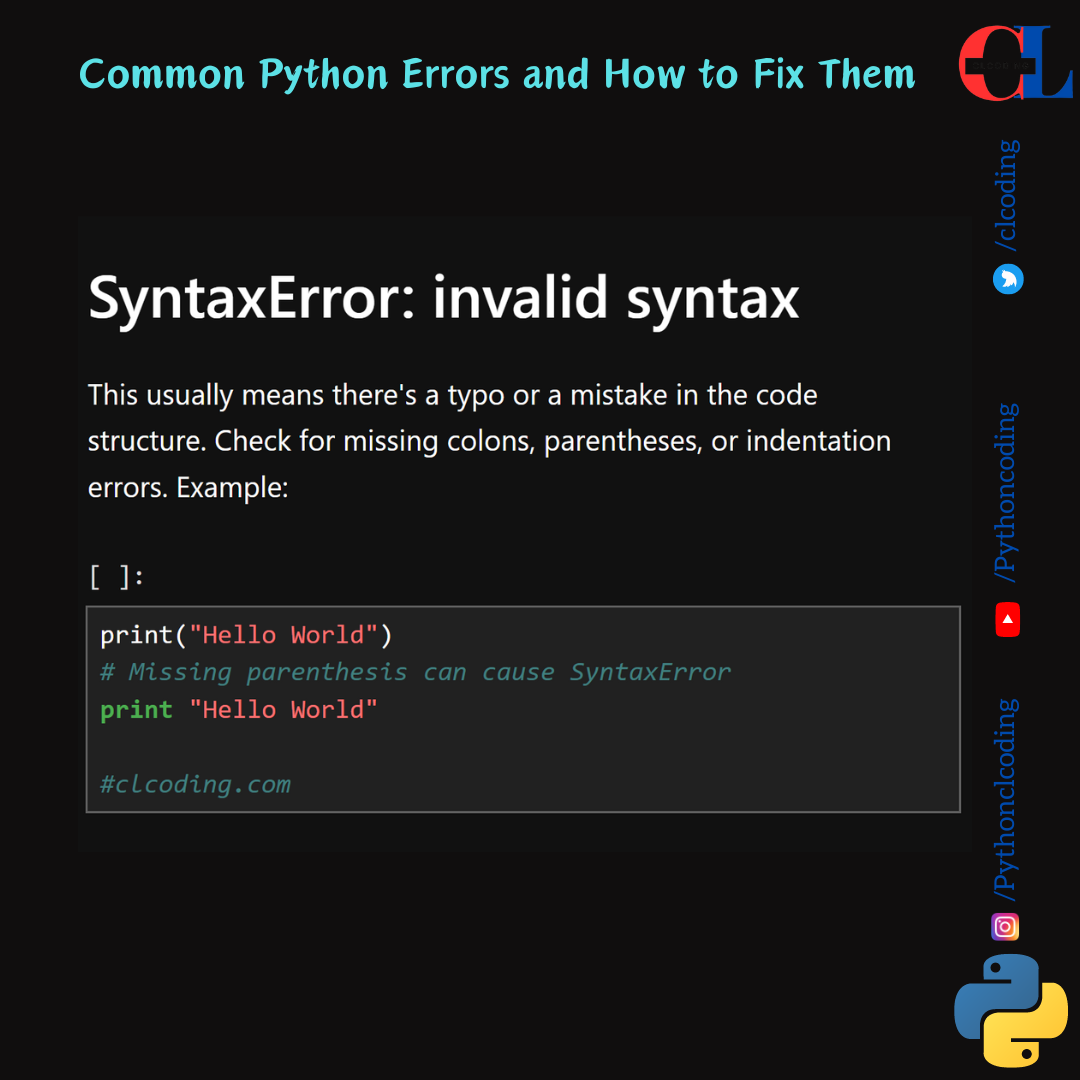











.png)
.png)
.png)


.png)


.png)
.png)




.png)




.png)
.png)







.png)

.png)
.png)






