Write Readable Code: Use descriptive variable names and write comments where necessary.Follow PEP 8: Adhere to Python's official style guide for formatting your code.Use Virtual Environments: Isolate project dependencies using virtualenv...
let's break down and explain each part of this code:my_dict = {1: 0, 0: [], True: False}result = all(my_dict)print(result)Step-by-Step ExplanationDictionary Creation:my_dict = {1: 0, 0: [], True: False}This line creates a dictionary my_dict...
# Importing necessary librariesimport PyPDF2import pyttsx3# Prompt user for the PDF file namepdf_filename = input("Enter the PDF file name (including extension): ").strip()# Open the PDF filetry: with open(pdf_filename, 'rb')...
Code:explain c = '13\t14' print(c.index('\t'))Solution and Explanation:Let's break down the code c = '13\t14' and print(c.index('\t')) to understand what it does:c = '13\t14'Here, we are assigning a string to the variable c.The string...
Step 1: Install Necessary LibrariesFirst, make sure you have matplotlib and seaborn installed. You can install them using pip:pip install matplotlib seaborn#clcoding.comStep 2: Import LibrariesNext, import the necessary libraries in your Python...
Code:lst = ['P', 20, 'Q', 4.50]item = iter(lst)print(next(item))Solution and Explanation: Let's break down the code and explain each part in detail:lst = ['P', 20, 'Q', 4.50]item = iter(lst)print(next(item))ExplanationCreating...
List comprehensions in Python provide a powerful and concise way to create lists. They are an essential part of any Python programmer's toolkit. Ready to make your code more Pythonic? Let's dive in!What is a List Comprehension?A list comprehension...
Introduction to Modern Statistics is a re-imagining of a previous title, Introduction to Statistics with Randomization and Simulation. The new book puts a heavy emphasis on exploratory data analysis (specifically exploring multivariate...
Code:h = [5, 6, 7, 8]h.pop()h.pop(0)print(h)Solution and Explanation: Let's break down the given Python code and explain what each line does:h = [5, 6, 7, 8]This line creates a list h with the elements 5, 6, 7, and 8.h = [5, 6, 7,...
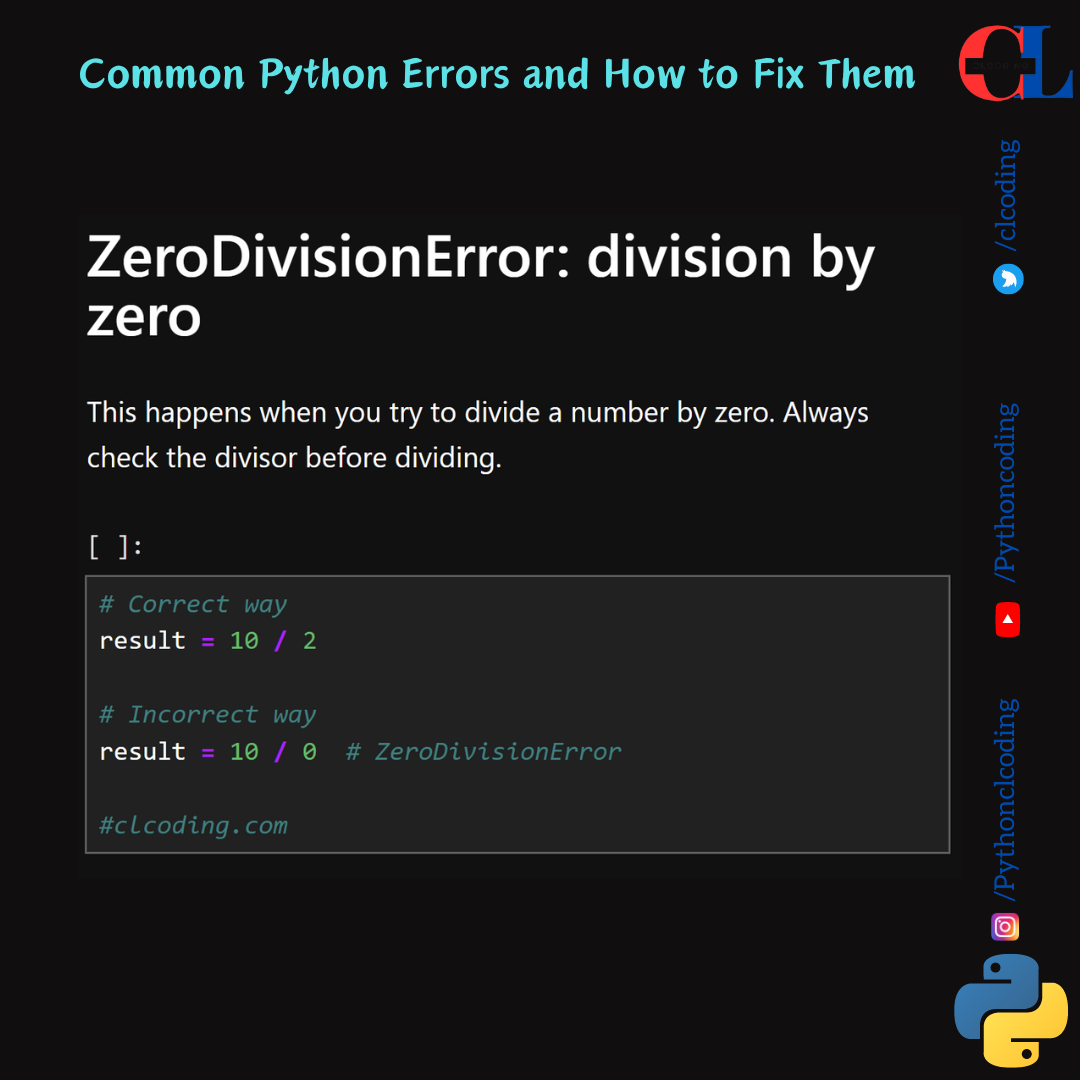
ZeroDivisionError: division by zeroThis happens when you try to divide a number by zero. Always check the divisor before dividing.# Correct wayresult = 10 / 2# Incorrect wayresult = 10 / 0 # ZeroDivisionError#clcoding.com IndentationError:...
Code:g = [1, 2, 3]h = [1, 2, 3]print(g is h) print(g == h) Solution and Explanation:In Python, the expressions g = [1, 2, 3] and h = [1, 2, 3] create two separate list objects that contain the same elements. When we use...
Code:str_a = "hello"str_b = "hello"print(str_a is str_b)print(str_a == str_b)Solution and Explanation: In Python, the statements str_a = "hello" and str_b = "hello" both create string objects that contain the same sequence...
.png)


.png)



.png)



























.png)


















